


When I first started my journey with programming, I would have never assumed that learning might actually end up with me knowing less. Or to say it in a clearer way, realising that I know less than I thought. It sounds ridiculous, but I would bet my granddad’s rusty old Volkswagen Golf 2 that I’m not the only one who has felt that way. Yes, I’m that confident about it! 😉 There is nothing to worry about, however: this realisation is completely normal and is even known in psychology as the Dunning-Kruger effect. The chart below might help you to visualise it:
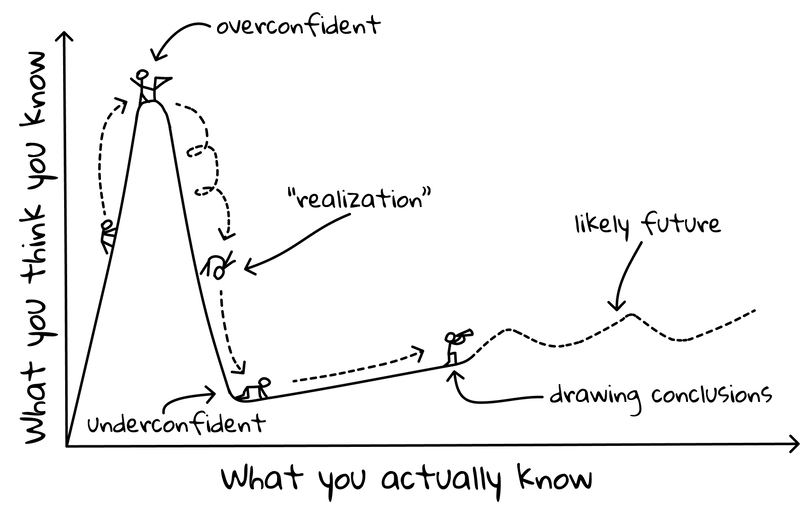
But after experiencing this effect for the first (and certainly not the last) time in my career as a professional Android Developer, I am sure of only two things: my grandpa’s car will still remain in his garage and programming will never stop surprising me. But that’s actually the coolest thing ever! 😇 Now, let me introduce you to the problem that made me rethink my approach to the knowledge I consume everyday. It all started with a very unintuitive question and even more surprising answer: Does RecyclerView recycle its views? 😇

Before we start
Although I wanted to make this article approachable to everyone, you can still find it very Android-specific. If you are not into getting too technical today, feel free to skip to the last paragraph, where I share the conclusions I drew after dealing with this situation. 😇
With that being said, let’s start our case. 😉
The suspect
Let’s say we develop a gallery picker for our app. Users can have two types of media files on their phone - an image or a video. RecyclerView is a list-viewer that allows us to display different views on one list. Now, let’s assume that due to some weird business decisions we find ourselves in a situation where we have to create a different view type for every media file type. It would look something like this:
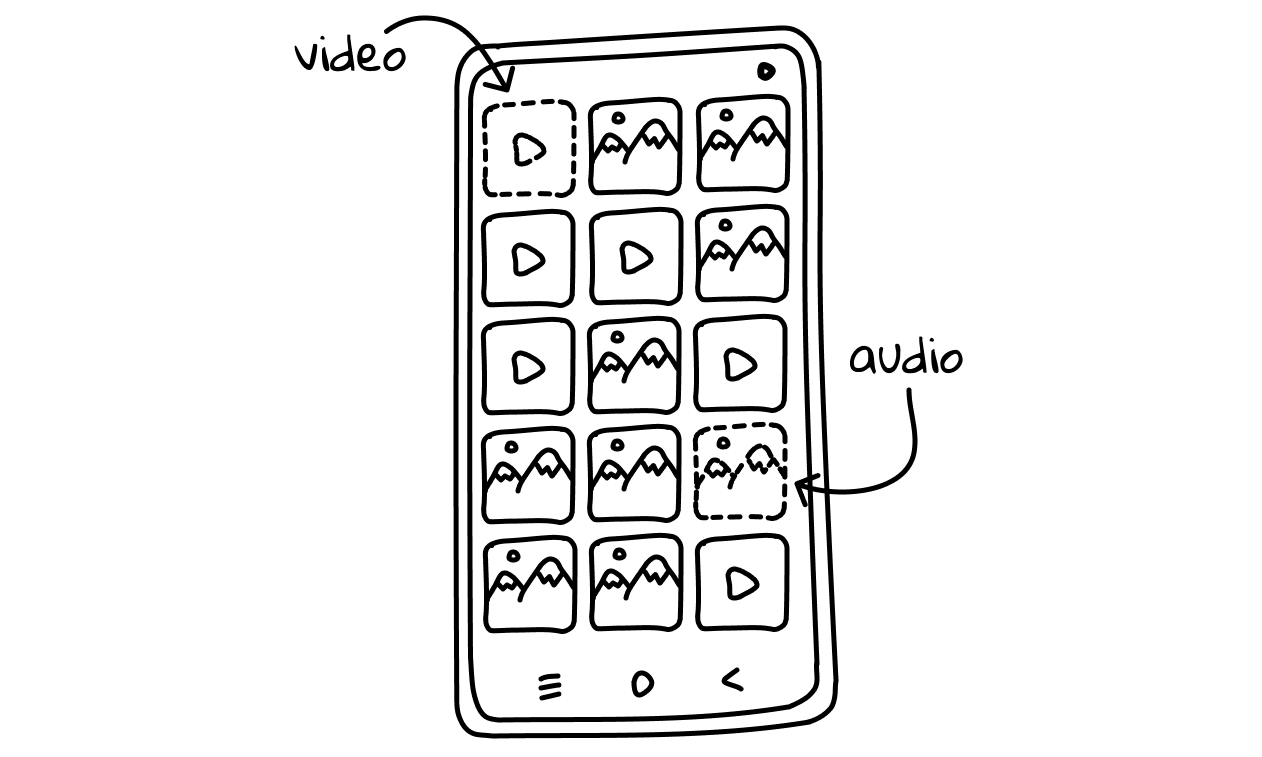
So we can have roughly 15 rows and 3 columns visible on a screen. Nothing fancy yet. 🎩
The problem
We already know that the strength of RecyclerView is that instead of creating a view for every item on the list, it manages a pool of views and inflates them as the user scrolls the app. Simplified process looks like this:
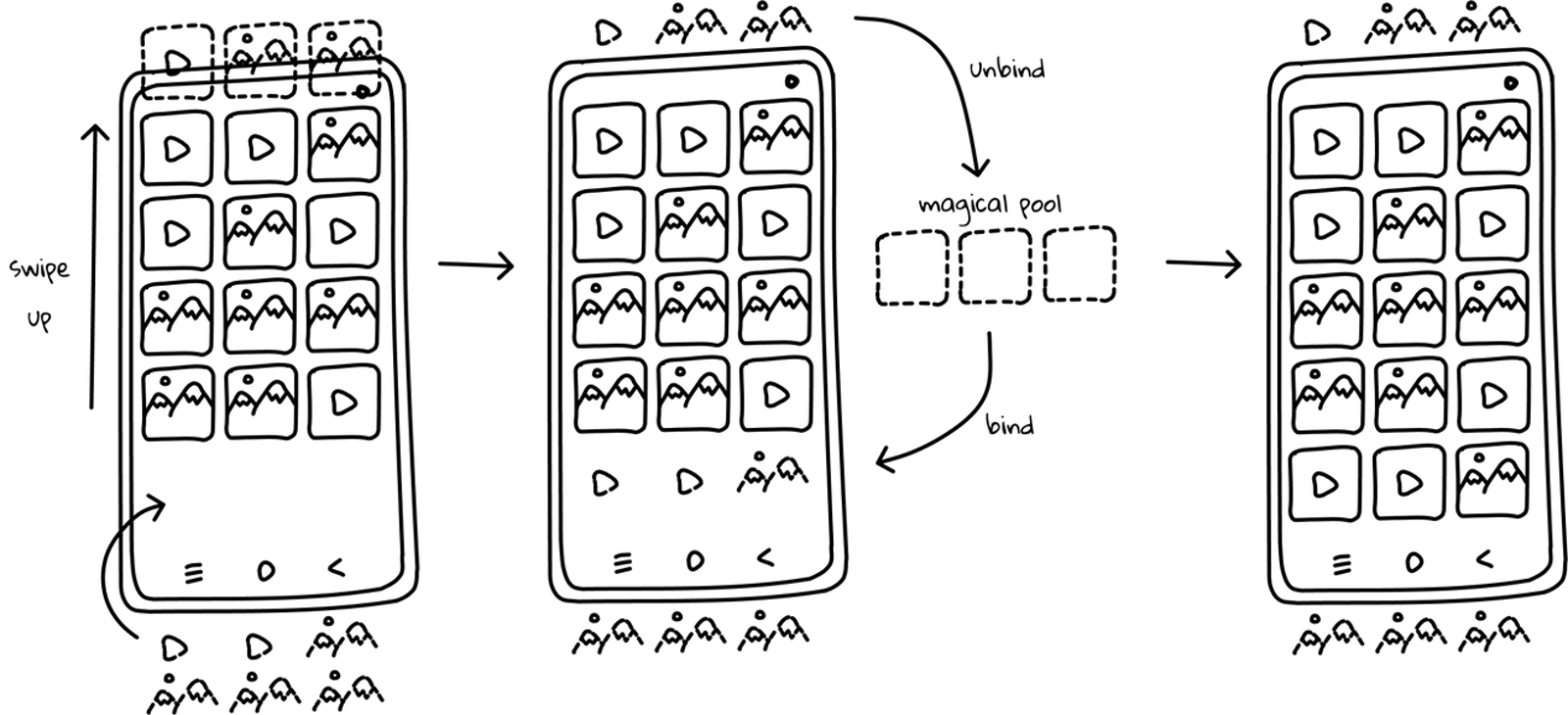
My assumption was that the onCreateViewHolder method should be called several times only when there are not enough ViewHolders available. Then, it should retrieve them from some ✨ magical pool ✨ , thus only onBindViewHolder should be called further during the scroll. Seems convenient, but believe me or not, I was struck dumb when I realised that in this situation, new ViewHolders are created every single time the user scrolls through the list! 😱
Okay, there is something fishy going on here… Yet, it happens everytime, no matter how deep we are into the list, or which direction we scroll. So there is nothing much left to do than to investigate this ambiguous situation further! I suggest we begin our search at the root of the problem, so let's first double-check RecyclerView’s method that is in charge of getting ViewHolders. It’s not very enjoyable to analyse, but don’t worry, I’ve done it for you. 😉 You can safely skip all lines of code but the ones where I shout BANANA, because everyone loves bananas, right? 😇

ViewHolder tryGetViewHolderForPositionByDeadline(int position,boolean dryRun, long deadlineNs) {
if (position < 0 || position >= mState.getItemCount()) {
throw new IndexOutOfBoundsException("Invalid item position " + position
+ "(" + position + "). Item count:" + mState.getItemCount()
+ exceptionLabel());
}
boolean fromScrapOrHiddenOrCache = false;
ViewHolder holder = null;
if (mState.isPreLayout()) {
holder = getChangedScrapViewForPosition(position);
fromScrapOrHiddenOrCache = holder != null;
}
if (holder == null) {
// BANANA 1 - first try to obtain the view from first-level cache
holder = getScrapOrHiddenOrCachedHolderForPosition(position, dryRun);
if (holder != null) {
if (!validateViewHolderForOffsetPosition(holder)) {
if (!dryRun) {
holder.addFlags(ViewHolder.FLAG_INVALID);
if (holder.isScrap()) {
removeDetachedView(holder.itemView, false);
holder.unScrap();
} else if (holder.wasReturnedFromScrap()) {
holder.clearReturnedFromScrapFlag();
}
recycleViewHolderInternal(holder);
}
holder = null;
} else {
fromScrapOrHiddenOrCache = true;
}
}
}
if (holder == null) {
final int offsetPosition = mAdapterHelper.findPositionOffset(position);
if (offsetPosition < 0 || offsetPosition >= mAdapter.getItemCount()) {
throw new IndexOutOfBoundsException("Inconsistency detected. Invalid item "
+ "position " + position + "(offset:" + offsetPosition + ")."
+ "state:" + mState.getItemCount() + exceptionLabel());
}
final int type = mAdapter.getItemViewType(offsetPosition);
if (mAdapter.hasStableIds()) {
// BANANA 2 - second try to obtain the view from first-level cache
holder = getScrapOrCachedViewForId(mAdapter.getItemId(offsetPosition),
type, dryRun);
if (holder != null) {
// update position
holder.mPosition = offsetPosition;
fromScrapOrHiddenOrCache = true;
}
}
if (holder == null && mViewCacheExtension != null) {
final View view = mViewCacheExtension
.getViewForPositionAndType(this, position, type);
if (view != null) {
holder = getChildViewHolder(view);
if (holder == null) {
throw new IllegalArgumentException("getViewForPositionAndType returned"
+ " a view which does not have a ViewHolder"
+ exceptionLabel());
} else if (holder.shouldIgnore()) {
throw new IllegalArgumentException("getViewForPositionAndType returned"
+ " a view that is ignored. You must call stopIgnoring before"
+ " returning this view." + exceptionLabel());
}
}
}
if (holder == null) {
if (DEBUG) {
Log.d(TAG, "tryGetViewHolderForPositionByDeadline("
+ position + ") fetching from shared pool");
}
// BANANA 3 - last hope to obtain view, this time from RecycledViewPool
holder = getRecycledViewPool().getRecycledView(type);
if (holder != null) {
holder.resetInternal();
if (FORCE_INVALIDATE_DISPLAY_LIST) {
invalidateDisplayListInt(holder);
}
}
}
if (holder == null) {
long start = getNanoTime();
if (deadlineNs != FOREVER_NS
&& !mRecyclerPool.willCreateInTime(type, start, deadlineNs)) {
return null;
}
// BANANA 4 - new view is created
holder = mAdapter.createViewHolder(RecyclerView.this, type);
if (ALLOW_THREAD_GAP_WORK) {
// only bother finding nested RV if prefetching
RecyclerView innerView = findNestedRecyclerView(holder.itemView);
if (innerView != null) {
holder.mNestedRecyclerView = new WeakReference<>(innerView);
}
}
long end = getNanoTime();
mRecyclerPool.factorInCreateTime(type, end - start);
if (DEBUG) {
Log.d(TAG, "tryGetViewHolderForPositionByDeadline created new ViewHolder");
}
}
}
// Other things happens, but let's skip them ;)
}
If you are curious about what’s going on here, you can find the answers in articles such as this one. What should bother us, is that RecyclerView goes through many steps to obtain the view before finally deciding to create a new one (BANANA 4). We can find two data structures involved there:
- mCachedViews (BANANA 1 and 2) - ArrayList of ViewHolders is our first level cache of not yet recycled ViewHolders. RecyclerView will use them if they exactly match the items that are next to display, or in other words, if it can skip binding and return these views just as they are. It works in FIFO manner, so the oldest views are moved to the pool described in the next point in order to make room for the new ones. This cache is common for all view types and the default size is 2. I will refer to it further as the Cache.
- mRecyclerPool (BANANA 3) - here are stored any other ViewHolders not used by RecyclerView at the time, waiting to be bound. Every view type manages its own pool, where default size is 5. I will refer to it further as the Pool.
So how are ViewHolders’ recycled? We could have a look at another “lovely” method called recycleViewHolderInternal, but I’ll spare you this time. 😉 Let’s go back to our example and imagine that the user scrolls one row of the views of the same type - what happens to them?
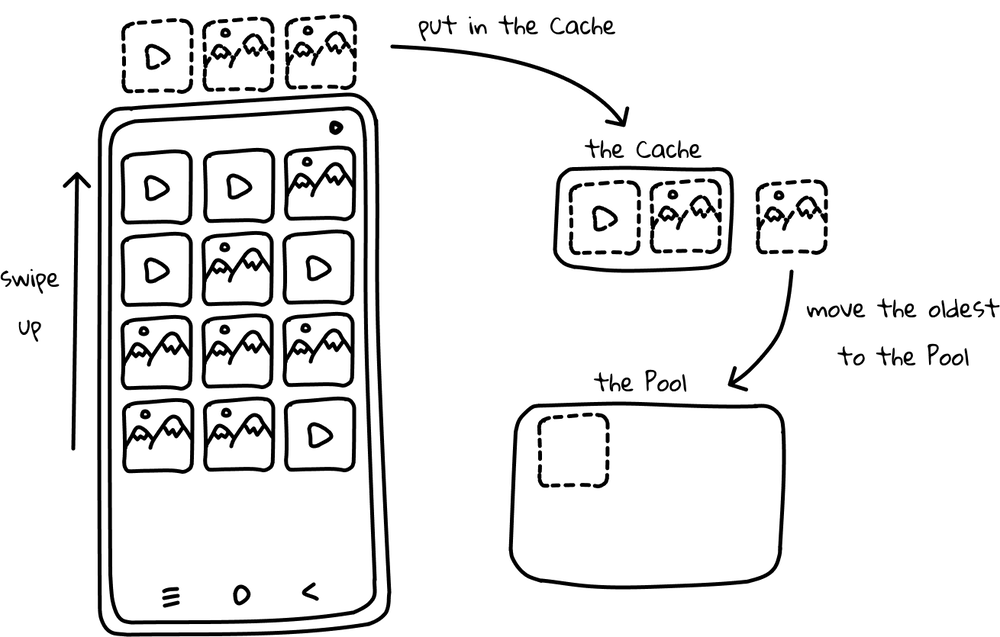
With a given cache size, we know that only two of these views will be stored in the Cache, so one would be added to the Pool. Quite simple so far. What happens, if we scroll back then? Views in the Cache are very likely to be suitable in such a situation, so they are obtained and returned without binding. The third one would be taken from the Pool and bound.
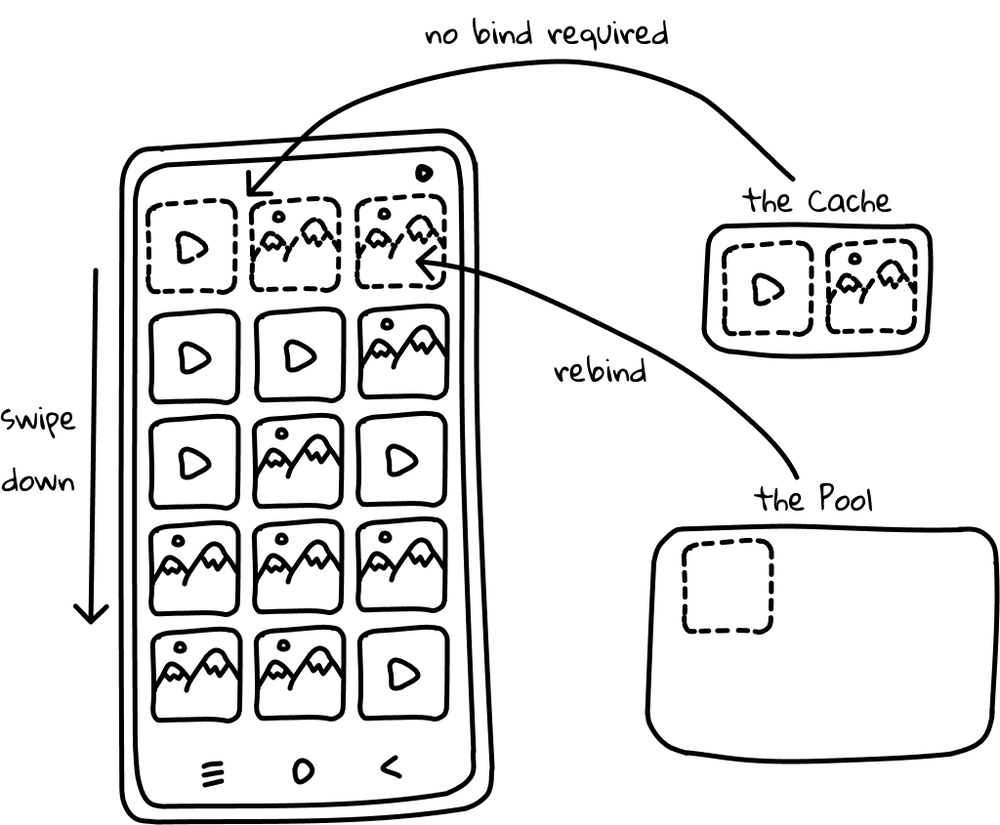
Great! Now we know how RecyclerView’s magic works! 🥳 With all that knowledge we can at last meet the Final Boss... 😈

The trespasser
Let’s say that gallery items are for some reason gathered in large groups by their view types. So we have 10 single images, then 10 single videos, then 10 ViewHolders’ of any type. Now, let’s scroll through all the items visible on the screen (15 for the record), so all single images are hidden and half of the videos appear. We already know the process, but let’s have a closer look at the pools’ sizes for every scrolled row.
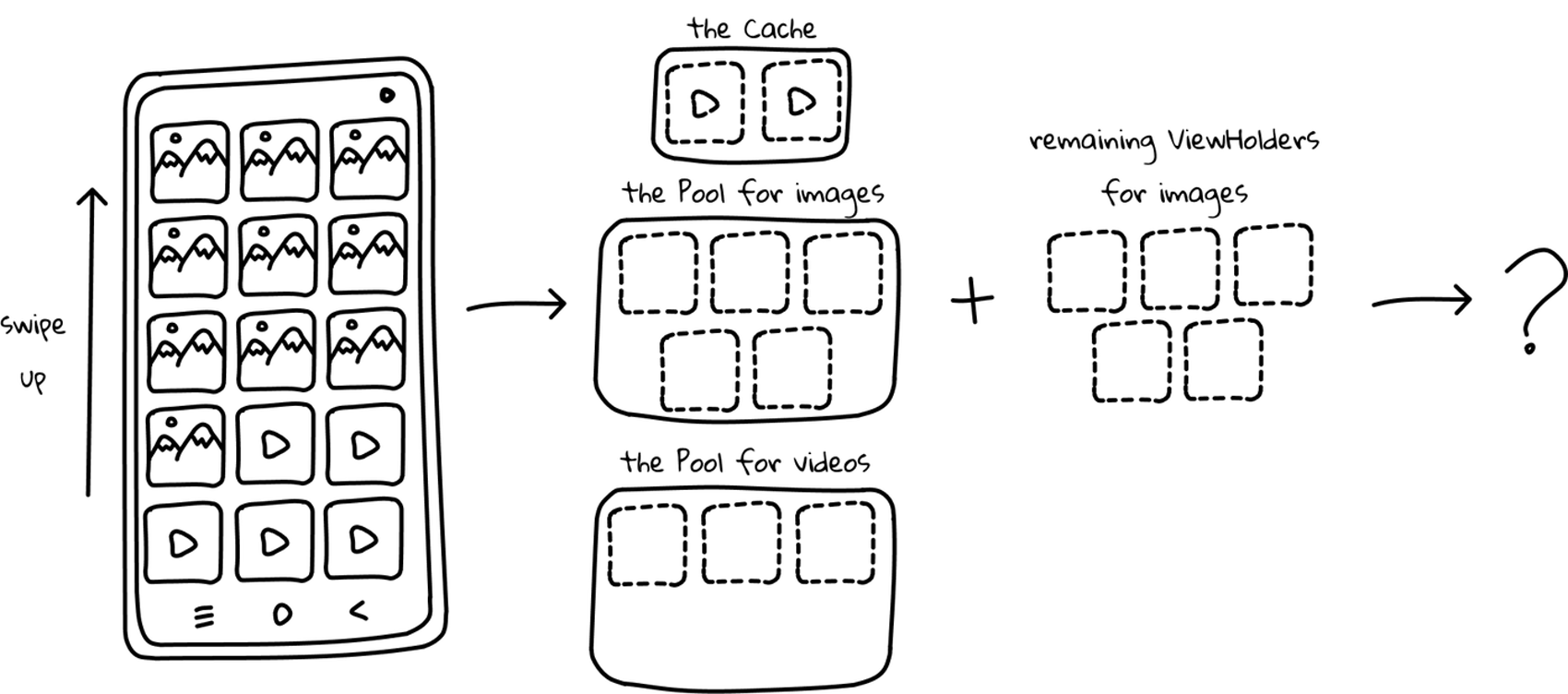
What happens to the extra views? Well, better to see the RecycledViewPool method for yourself…
public void putRecycledView(ViewHolder scrap) {
final int viewType = scrap.getItemViewType();
final ArrayList<ViewHolder> scrapHeap = getScrapDataForType(viewType).mScrapHeap;
if (mScrap.get(viewType).mMaxScrap <= scrapHeap.size()) {
return; // BANANA DOWN - ViewHolder is igonred
}
if (DEBUG && scrapHeap.contains(scrap)) {
throw new IllegalArgumentException("this scrap item already exists");
}
scrap.resetInternal();
scrapHeap.add(scrap);
}
They are literally destroyed. Our poor little ViewHolders...
You probably know what we are up to by now, but let’s look what happens with the views when we scroll back to the top:
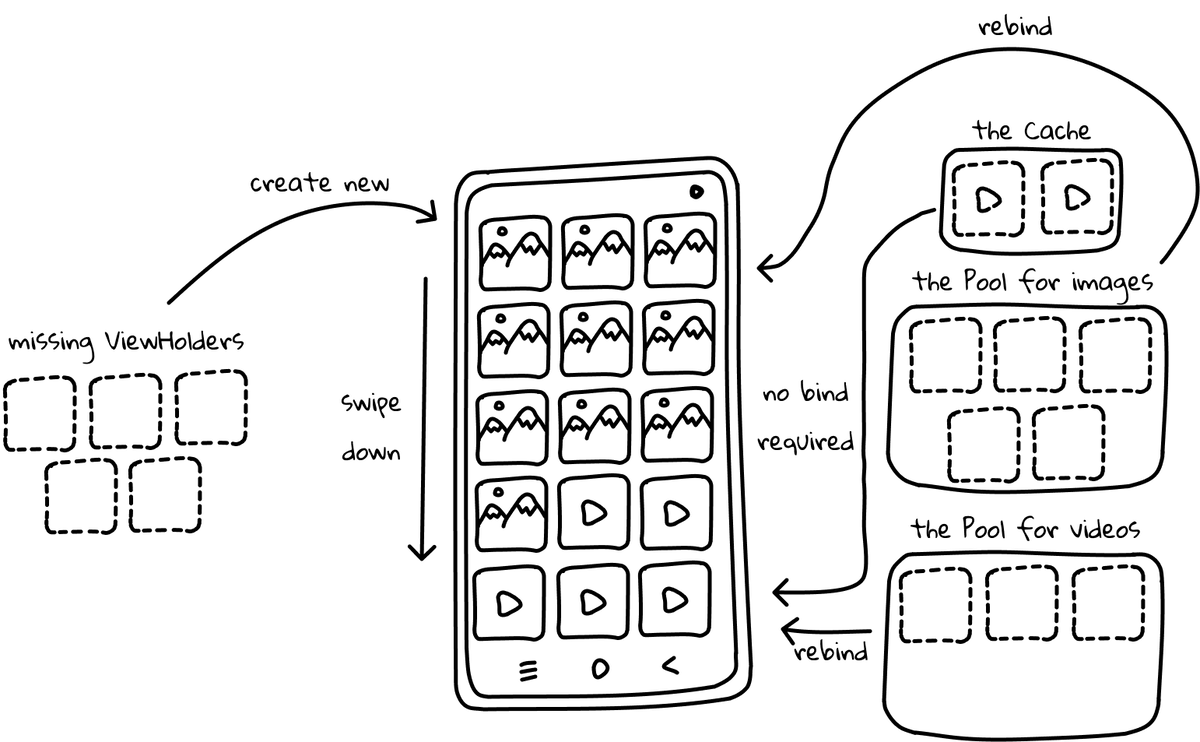
Sadly, it will happen every single time the user scrolls. Wait, so RecyclerView does not fulfill its duty?! Everything was a lie…. 😢 But why? Why does it create fixed pools that are unable to contain all the ViewHolders? To be honest, I couldn’t find a satisfactory answer to this question. I couldn’t find a justified answer in the docs for the default values choices either.
The solution
Yet there is a light at the end of the tunnel and it’s very simple: just increase the default values!
recyclerView.setItemViewCacheSize(size = TODO())
recyclerView.recycledViewPool.setMaxRecycledViews(viewType = TODO(), max = TODO())
But undoubtedly, a bad taste remains in our mouths... unless we admit that there is nothing wrong with RecyclerView?
“He has gone mad!” - you probably think, but hear me out first. RecyclerView was created in order to optimise by reusing views. Situations like the ones described in this article are just an unusual mix of the random distribution of views of multiple types, that are so small that many of them could be displayed at the same time on a screen. The views themselves are not “heavy” - we still need to bind them regardless of their origin and this is where the most action takes place. In other words, even with default values RecyclerView really recycles its views! And it does it in a very efficient way. If you still do not believe me, think about a totally opposite situation - we display large and heavy views (like posts in social apps), where barely two are visible at the time on the screen. Still think 2 + 5 is not enough? 😉
Reflection
So what did I do? After consultations with my colleagues I decided to multiply the default pools by the number of rows and it solved “the issue-that-in-fact-is-not-an-issue”. Do I advise you to do the same? Absolutely not! It might still be foggy, but the goal of this article was to persuade you to never let yourself be put on tracks built by somebody else. The internet is full of great solutions that we can both agree on. But great does not mean the best. The solution being introduced by a big tech company like Google isn’t automatically the best one, neither is the one your senior suggests, or the one suggested by your mum, dog or (put anyone else you like here), nor even the fact it worked well enough for somebody else, or that it was the most upvoted solution on StackOverflow. 😉 These are just clues that it might work well for you! But what happens, if you ask - “why might it be a good solution for me”? Well, you can answer yourself, that Google puts a lot of effort into making their solution work for most cases, your senior has probably dealt with such situations in the past and tried several other methods already, your mum is always right (sigh) and you are the most precious thing in your dog’s life, so it’s obvious it wants the best for you! These answers might be obvious, yet you had to find them, so you probably learned your own way of figuring them out. 😇 So one more time: I bet my grandpa’s rusty Volkswagen Golf 2, that during your career, you might still find yourself being a bit doubtful about some things. That is inevitable, but you will also realise that doubting things is actually an efficient way to learn. And yes, I’m still sure the car will be staying in the garage. 😉



